2025 State of AI Report and Predictions
Published on October 10, 2025 5:30 PM GMT
X (formerly Twitter)
Nathan Benaich (@nathanbenaich) on X
Moving into Safety: budgets are anemic. All 11 major US safety orgs will spend $133M in 2025…less than frontier labs burn in a day.
, with lots of fun slides and a full video presentation. They’ve been consistently solid, providing a kind of outside general view.
<img src="
https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/AvKjYYYHC93JzuFCM/ala4eehmaitdgi9wcnsn" alt="">

State of AI Report 2025
The State of AI Report analyses the most interesting developments in AI. Read and download here.
that doesn’t bear repeating.
Qwen The Fine Tune King For Now
Nathan Benaich: Once a “Llama rip-off,” @Alibaba_Qwen now powers 40% of all new fine-tunes on @huggingface. China’s open-weights ecosystem has overtaken Meta’s, with Llama riding off into the sunset…for now.
I highlight this because the ‘for now’ is important to understand, and to note that it’s Qwen not DeepSeek. As in, models come and models go, and especially in the open model world people will switch on you on a dime. Stop worrying about lock-ins and mystical ‘tech stacks.’
Rise Of The Machines
Robots now reason too. “Chain-of-Action” planning brings structured thought to the physical world – from AI2’s Molmo-Act to Gemini Robotics. Massive amounts of effort are thrown into the mix, expect lots of progress here…
Model Context Protocol Wins Out
.@AnthropicAI‘s Model Context Protocol is the new USB-C of AI. A single standard to connect models to tools, already embedded in ChatGPT, Gemini, Claude, and VS Code, has taken shape. But not without emerging security risks…
Benchmarks Are Increasingly Not So Useful
I note this next part mostly because it shows the Different Worlds dynamic:
Nathan Benaich: The frontier fight is relentless.

X (formerly Twitter)
OpenAI (@OpenAI) on X
OpenAI’s mission is to ensure that artificial general intelligence benefits all of humanity. We’re hiring: https://t.co/dJGr6Lg202
‘s stays there longer. Timing releases has become its own science…not least informing financing rounds like clockwork.
<img src="
https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/AvKjYYYHC93JzuFCM/igvsuqok1fueefw2a7fy" alt="">
They’re citing LMArena and Artificial Analysis. LMArena is dead, sir. Artificial Analysis is fine, if you had to purely go with one number, which you shouldn’t do.
The DeepSeek Moment Was An Overreaction
Once more for the people in the back or the White House:
.@deepseek_ai “$5M training run” deep freak was overblown. Since the market realised the fineprint in the R1 paper, that’s led to Jevons paradox on steroids: lower cost per run → more runs → more compute needed, buy more NVIDIA.
… China leads in power infrastructure too, adding >400GW in 2024 vs 41GW for the US. Compute now clearly runs on geopolitics.
Capitalism Is Hard To Pin Down
Then we get to what I thought was the first clear error:
Now, let’s switch gears into Politics. The US Government is turning capitalist. Golden shares in US Steel, stakes in Intel and MP Materials, and revenue cuts from NVIDIA’s China sales. New-age Industrial policy?
Not capitalist. Socialist.
The term for public ownership of the means of production is socialist.
Unless this meant ‘the US Government centrally maximizing the interests of certain particular capitalists’ or similarly ‘the US Government is turning into one particular capitalist maximizing profits.’ In which case, I’m not the one who said that.
The Odds Are Against Us And The Situation Is Grim
The AI Safety Institute network has collapsed. Washington ditched attending meetings altogether, while the US and UK rebranded “safety” into “security.”
I don’t think this is fair to UK AISI, but yes the White House has essentially told anyone concerned about existential risk or seeking international coordination of any kind to, well, you know.
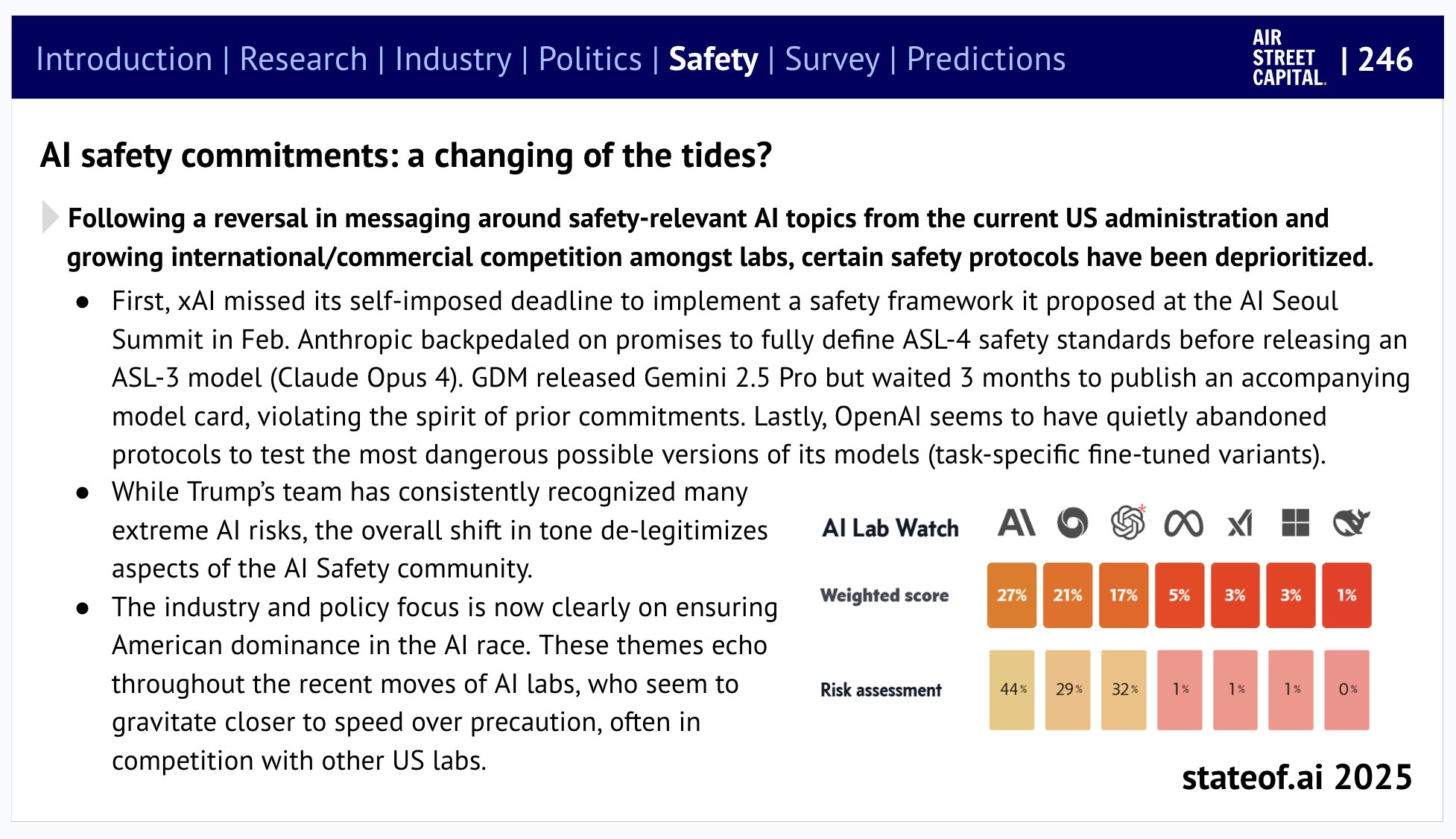
Moving into Safety: budgets are anemic. All 11 major US safety orgs will spend $133M in 2025…less than frontier labs burn in a day.
<img src="
https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/AvKjYYYHC93JzuFCM/zlshfqxoq8akgpd57mqo" alt="">
I like that this highlights Anthropic’s backpedaling, GDM’s waiting three weeks to give us a model card and xAI’s missing its deadline. It’s pretty grim.
What I disagree with here is the idea that all of that has much to do with the Trump Administration. I don’t want to blame them for things they didn’t cause, and I think they played only a minor role in these kinds of safety failures. The rhetoric being used has shifted to placate them, but the underlying safety work wouldn’t yet be substantially different under Harris unless she’d made a major push to force that issue, well beyond what Biden was on track to do. That decision was up to the labs, and their encounters with reality.
But yes, the AI safety ecosystem is tiny and poor, at risk of being outspent by one rabid industry anti-regulatory super-PAC alone unless we step things up. I have hope that things can be stepped up soon.
Cyber and alignment risks accelerate. Models can now fake alignment under supervision, and exploit code faster than humans fix it.
They Grade Last Year’s Predictions
They then grade their predictions, scoring themselves 5/10, which is tough but fair, and made me confident I can trust their self-grading. As Sean notes they clearly could have ‘gotten away with’ claiming 7/10, although I would have docked them for trying.

X (formerly Twitter)
Seán Ó hÉigeartaigh (@S_OhEigeartaigh) on X
Two of the things I really appreciate is that (a) they make and review predictions each year and (b) unlike some other predictors they grade themse...
h: Two of the things I really appreciate is that (a) they make and review predictions each year and (b) unlike some other predictors they grade themselves HARSHLY. Several of these ‘no’s are distinctly borderline, they could have given themselves 7-8/10 and I don’t think I would have held it against them.
A $10B+ investment from a sovereign state into a US large AI lab invokes national security review.
No, although on technicalities, but also national security review hahaha.
An app or website created solely by someone with no coding ability will go viral (e.g. App Store Top-100).
Yes, Formula Bot.
Frontier labs implement meaningful changes to data collection practices after cases begin reaching trial.
Yes, Anthropic and the whole $1.5 billion fiasco.
Early EU AI Act implementation ends up softer than anticipated after lawmakers worry they’ve overreached.
No, they say, but you could definitely make a case here.
An open source alternative to OpenAI o1 surpasses it across a range of reasoning benchmarks.
Yes, r1 did this, although as stated this was an easy call.
Challengers fail to make any meaningful dent in NVIDIA’s market position.
Yes, again relatively easy call on this time frame.
Levels of investment in humanoids will trail off, as companies struggle to achieve product-market fit.
No, investment grew from $1.4b to $3b. I half-kid that spiritually this is kind of counts as a win in AI, it only doubled, that’s kind of a trail off?
But no, seriously, the robots are coming.
Strong results from Apple’s on-device research accelerates momentum around personal on-device AI.
No, Apple Intelligence and their research department flopped. On device AI is definitely growing anyway.
A research paper generated by an AI Scientist is accepted at a major ML conference or workshop.
Yes, AI Scientist-v2 at an ICLR workshop.
A video game based around interacting with GenAI-based elements will achieve break-out status.
Nope. This continues to be a big area of disappointment. Not only did nothing break out, there wasn’t even anything halfway decent.
Their Predictions for 2026
Here are their predictions for 2026. These are aggressive, GPT-5-Pro thinks their expected score is only 3.1 correct. If they can hit 5/10 again I think they get kudos, and if they get 7/10 they did great.
I made my probability assessments before creating Manifold markets, to avoid anchoring, and will then alter my assessment based on early trading.
I felt comfortable creating those markets because I have confidence both that they will grade themselves accurately, and that LLMs will be strong enough in a year to resolve these questions reasonably. So my resolution rule was, their self-assessment wins, and if they don’t provide one I’ll feed the exact wording into Anthropic’s strongest model – ideally this should probably be best 2 out of 3 of Google, OpenAI and Anthropic, but simplicity is good.
A major retailer reports >5% of online sales from agentic checkout as AI agent advertising spend hits $5B.
Total advertising spending in America in 2025 was ~$420 billion.
I think this is ambitious, but variance here is really high and the correlation between the two numbers is large.
GPT-5-Pro says 18%, Sonnet says 8%, I think it’s more plausible than that. Maybe 25%?

Manifold
SOAI#1: A major retailer reports >5% of online sales from agentic checkout as AI agent advertising spend hits $5B.
27% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #1: A major retailer reports >5% ...
so that seems good.
A major AI lab leans back into open-sourcing frontier models to win over the current US administration.
GPT-5-Pro says 22%, Sonnet says 25%.
I don’t see it, if this means ‘release your frontier model as an open model.’ Who? I would only count at most five labs as major, and Meta (who is pushing it in terms of counting) is already open. The only realistic option here is xAI.
That goes double if you include the conditional ‘to win over the current US administration.’ There’s a lot of other considerations in such a move.
Thus, I’d sell this down to 15%, but it’s hard to be too confident about Elon?

Manifold
SOAI#2: A major AI lab leans back into open-sourcing frontier models to win over the current US administration
18% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #2: A major AI lab leans back int...
but tends to be too high in such spots, so I still would be a seller.
Open-ended agents make a meaningful scientific discovery end-to-end (hypothesis, expt, iteration, paper).
Define ‘meaningful’ and ‘end to end’ in various ways? Always tricky.
I’m actually optimistic, if we’re not going to be sticklers on details.
GPT-5-Pro says 36%, Sonnet is deeply skeptical and says 15%. If I knew we had a reasonable threshold for ‘meaningful’ and we could get it turned around, I’d be on the optimistic end, but I think Sonnet is right that if you count the paper the timeline here is pretty brutal. So I’m going to go with 35%.

Manifold
SOAI#3: Open-ended agents make a meaningful scientific discovery end-to-end (hypothesis, expt, iteration, paper).
50% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #3: Open-ended agents make a mean...
with active trading, with Nathan Metzger noting the issue of defining a meaningful discovery and Brian Holtz noting the issue of how much assistance is allowed. I’m willing to interpret this as an optimistic take on both feasibility and what would count and go to 50%.
A deepfake/agent-driven cyber attack triggers the first NATO/UN emergency debate on AI security.
It would take really a lot to get this to trigger. Like, really a lot.
There’s even an out that if something else triggers a debate first, this didn’t happen.
GPT-5-Pro said 25%, Sonnet said 12% and I’m with Sonnet.

Manifold
SOAI#4: A deepfake/agent-driven cyber attack triggers the first NATO/UN emergency debate on AI security
25% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #4: A deepfake/agent-driven cyber...
down the middle. I’m still with Sonnet.
A real-time generative video game becomes the year’s most-watched title on Twitch.
I’ll go ahead and take the no here. Too soon. Generative games are not as interesting as people think, and they’re doubling down on the 2024 mistake.
GPT-5-Pro has this at 14%, Sonnet says 3%. I think Sonnet is a bit overconfident, let’s say 5%, but yeah, this has to overcome existing behemoths even if you make something great. Not gonna happen.

Manifold
SOAI#5: A real-time generative video game becomes the year’s most-watched title on Twitch.
7% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #4: A real-time generative video ...
, which is basically their version of ‘not gonna happen’ given how the math works for long shots.
“AI neutrality” emerges as a foreign policy doctrine as some nations cannot or fail to develop sovereign AI.
I doubt they’ll call it that, but certainly some nations will opt out of this ‘race.’
GPT-5-Pro said 25%, Sonnet says 20%. I agree if this is a meaningful ‘neutrality’ in the sense of neutral between China and America on top of not rolling one’s own, but much higher if it simply means that nations opt out of building their own and rely on a frontier lab or a fine tune of an existing open model. And indeed I think this opt out would be wise for many, perhaps most.

Manifold
SOAI#6: “AI neutrality” emerges as a foreign policy doctrine as some nations cannot or fail to develop sovereign AI
22% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #6: “AI neutrality” emerges a...
. Given the ambiguity issues, that’s within reasonable range.
A movie or short film produced with significant use of AI wins major audience praise and sparks backlash.
GPT-5-Pro says 68%, Sonnet says 55%. I’d be a buyer there, normally a parlay is a rough prediction but there would almost certainly be backlash conditional on this happening. A short film counts? I’m at more like 80%.

Manifold
SOAI#7: A movie or short film produced with significant use of AI wins major audience praise and sparks backlash
68% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #7: A movie or short film produce...
. That seems low to me, but I can moderate to 75%.
A Chinese lab overtakes the US lab dominated frontier on a major leaderboard (e.g. LMArena/Artificial Analysis).
I’d bet big against a Chinese lab actually having the best model at any point in 2026, but benchmarks are not leaderboards.
I’d be very surprised if this happened on Artificial Analysis. Their evaluation suite is reasonably robust.
I’d be less surprised if this happened on LM Arena, since it is rather hackable, if one of the major Chinese labs actively wanted to do this there’s a decent chance that they could, the way Meta hacked through their model for a bit.
I still think this is an underdog. GPT-5-Pro said 74%, Sonnet says 60% and is focusing on Arena as the target. It only has to happen briefly. I think the models are too optimistic here, but I’ll give them maybe 55% because as worded this includes potential other leaderboards too.

Manifold
SOAI#8: A Chinese lab overtakes the US lab dominated frontier on a major leaderboard (e.g. LMArena/Artificial Analysis)
42% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #8: A Chinese lab overtakes the U...
, and on reflection yeah I was being a coward and moderating my instincts too much, that’s more like it. I’d probably buy there small because the resolution criteria is relatively generous, fair 40%.
Datacenter NIMBYism takes the US by storm and sways certain midterm/gubernatorial elections in 2026.
Threshold is always tricky with such questions. If we’re talking at least two races for governor, house or senate, I think this is not that likely to happen, nor is it likely to be very high on the list of issues in general. I’m on no.
GPT-5-Pro says 23%, Sonnet says 18%. I’d probably say more like 15%. If you expand this so ‘a bunch of local races around potential cites’ counts including for ‘take by storm’ then I could go higher.

Manifold
SOAI#9: Datacenter NIMBYism takes the US by storm and sways certain midterm/gubernatorial elections in 2026
26% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #9: Datacenter NIMBYism takes the...
. I’ll adjust to 25% on that, they might especially have a better sense of what would count, but this particular AI issue ‘taking the US by storm’ that often seems like a stretch.
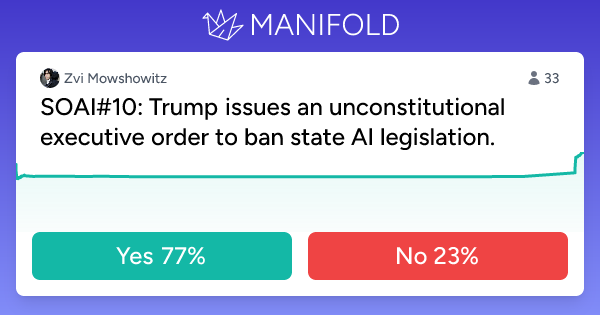
Trump issues an unconstitutional executive order to ban state AI legislation.
I love that they explicitly say it will be unconstitutional.
I do agree that if he did it, it would be unconstitutional, although of course it will be 2026 so it’s possible he can Just Do Things and SCOTUS will shrug.
Both GPT-5-Pro and Sonnet say 35% here. That feels high but I can definitely see this happening, I agree with Sonnet that it is ‘on brand.’ 25%?
Manifold
SOAI#10: Trump issues an unconstitutional executive order to ban state AI legislation.
77% chance. This market resolves to YES or NO as per the 2026 State of AI Report's self grading of its prediction #10: Trump issues an unconstituti...
. Okay, sure, I’ll accept that and creep fair down a bit.
Indeed, despite nothing ever happening, do many things come to pass. It would be cool to have my own bold predictions for 2026, but I think the baseline scenario is very much a boring ‘incremental improvements, more of the same with some surprising new capabilities, people who notice see big improvements but those who want to dismiss can still dismiss, the current top labs are still the top labs, a lot more impact than the economists think but nothing dramatic yet, safety and alignment look like they are getting better and for short term purposes they are, and investment is rising, but not in ways that give me faith that we’re making Actual Progress on hard problems.’
I do think we should expect at least one major vibe shift. Every time vibes shift, it becomes easy to think there won’t soon be another vibe shift. There is always another vibe shift, it is so over and then we are so back, until AGI arrives and perhaps then it really is over whether or not we are also so back. Two shifts is more likely than zero. Sometimes the shifts are for good reasons, usually it is not. The current ‘powers that be’ are unlikely to be the ones in place, with the same perspectives, at the end of 2026.
https://www.lesswrong.com/posts/AvKjYYYHC93JzuFCM/2025-state-of-ai-report-and-predictions#comments
https://www.lesswrong.com/posts/AvKjYYYHC93JzuFCM/2025-state-of-ai-report-and-predictions


