Discussed a fascinating idea for a foundation model tool at lunch today: interactive navigation in embedding space.
Right now, you prompt most generative models with human language. That works, but itŌĆÖs imprecise and coarse. If youŌĆÖre generating an image of an outside scene, and you want the sunlight ever so slightly brighter, you could add the phrase ŌĆ£and ever so slightly brighterŌĆØ to the prompt, and it might work, but itŌĆÖs clunky, and not great, and clearly doesnŌĆÖt scale. Maybe good enough for recreational use cases; clearly not professional grade.
What you really want to do is move your target in embedding space directly, without the lossy indirection of going through human language. Ideally, youŌĆÖd have a dial that mapped directly to sunlight luminance, and you could bump it up just a bit. Similar to temperature for LLMs, but for fine control over direction and distance in high-dimensionality embedding space, as opposed to overall stochasticity.
Imagine a big mixing board at a professional music studio. You generate an initial image as a starting point, and the model analyzes it and gives you the top 100 principal components as vectors in embedding space, each [grounded](
https://techcommunity.microsoft.com/blog/fasttrackforazureblog/grounding-llms/3843857 ) to the closest embedding and human word that describes them. Smiles, spikiness, wood, buttons, height above the ground, crowd density, all sorts of concepts, each with a knob you can dial up or down. They wonŌĆÖt be entirely independent, so cranking up smiles may also move the warmth, happiness, and sociability knobs, which is ok.
ItŌĆÖs a complicated UI! Definitely not as approachable as ŌĆ£just type into the text box.ŌĆØ And typing into a text box has gotten us pretty far! But if weŌĆÖre stuck with human language as our main interface to generative models, thatŌĆÖs extremely limiting. Professionals wonŌĆÖt tolerate that for long; they need more powerful, fine grained interfaces that give them a high degree of interactive control and ability to iterate. Language prompts may have gotten us here, as they say, but they may not get us there.
AI researchers will note that this has lots of prior art in grounding and interpretability, among other areas. IŌĆÖm no expert, IŌĆÖd love to hear any thoughts!
 )
)
 )
)




 )
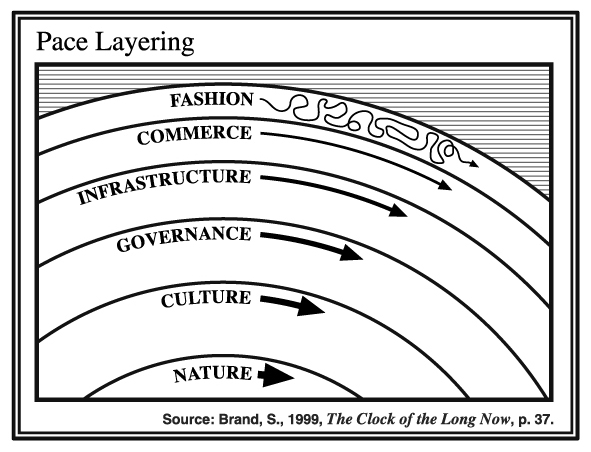
Product includes devices like XBox, TiVo, and PalmPilot; apps like Firefox, MS Office, and Lotus 1-2-3; and services like Google, Facebook, and Wikipedia.
Components include libraries and frameworks: glibc, LLVM, Django, React, Docker, Arduino, etc.
Organizations involve some form of human governance, eg companies like Bell Labs, IBM, Microsoft, and ARM; non-profits like ICANN, the FSF, and the Linux and Apache foundations; and standards bodies like IETF, W3C, ECMA, and OASIS.
Standards are open via standards bodies, proprietary to individual companies, and de facto. Examples include networking protocols like TCP/IP, HTTP, and SMTP; file formats like HTML, JPEG, and WAV; character encodings like ASCII, ISO 8859-1, and Unicode; operating system interfaces like Win32, POSIX, and Cocoa; and hardware languages like Verilog, VHDL, CUDA, FPGAs, etc.
Computer science and electrical engineering are the academic fields that provide the direct foundations for software and hardware, respectively, and math and physics underneath them. Number theory and cryptography, information theory, combinatorics, Boolean logic, digital and analog circuit design, and arguably even materials science processes like EUV lithography all live here.
IŌĆÖm far from the first to think along these lines. [Erik Samsoe on Twitter](
)
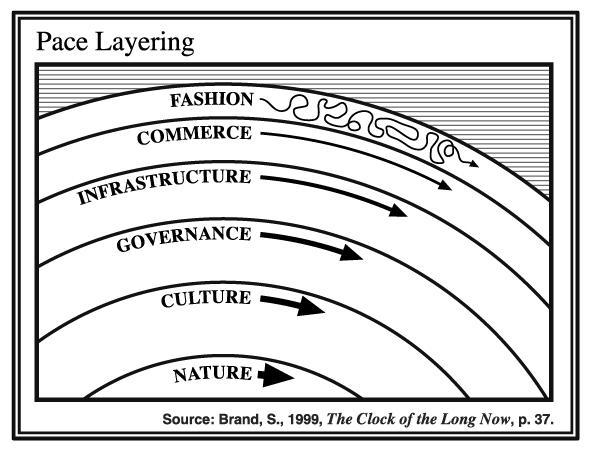
Product includes devices like XBox, TiVo, and PalmPilot; apps like Firefox, MS Office, and Lotus 1-2-3; and services like Google, Facebook, and Wikipedia.
Components include libraries and frameworks: glibc, LLVM, Django, React, Docker, Arduino, etc.
Organizations involve some form of human governance, eg companies like Bell Labs, IBM, Microsoft, and ARM; non-profits like ICANN, the FSF, and the Linux and Apache foundations; and standards bodies like IETF, W3C, ECMA, and OASIS.
Standards are open via standards bodies, proprietary to individual companies, and de facto. Examples include networking protocols like TCP/IP, HTTP, and SMTP; file formats like HTML, JPEG, and WAV; character encodings like ASCII, ISO 8859-1, and Unicode; operating system interfaces like Win32, POSIX, and Cocoa; and hardware languages like Verilog, VHDL, CUDA, FPGAs, etc.
Computer science and electrical engineering are the academic fields that provide the direct foundations for software and hardware, respectively, and math and physics underneath them. Number theory and cryptography, information theory, combinatorics, Boolean logic, digital and analog circuit design, and arguably even materials science processes like EUV lithography all live here.
IŌĆÖm far from the first to think along these lines. [Erik Samsoe on Twitter](