
10 major VPN companies are run the people of same group.
so think about #privacy again when paying for it.
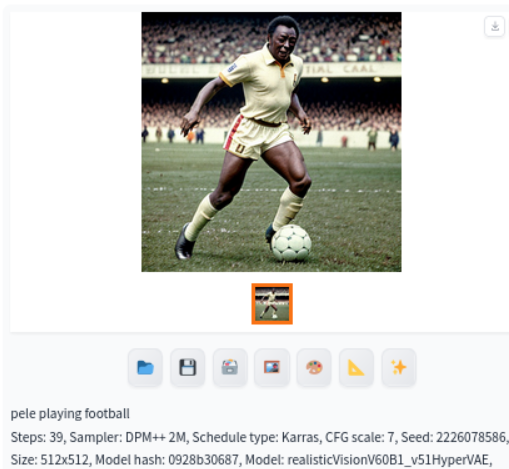 #pele just with near default settings
#pele just with near default settings
 am sure better n more power start real dev are doing on field - well it's a start after all.
am sure better n more power start real dev are doing on field - well it's a start after all.

